

Everyone is rushing toward AI agents right now. LinkedIn is full of posts about “autonomous AI agents transforming the enterprise.” Vendors are slapping “agentic” on everything. And I keep seeing the same pattern from professionals who reach out to me: they spent three months watching YouTube videos and building toy chatbots, and now they’re stuck.
Here’s what nobody tells you. The jump from “I can use ChatGPT” to “I can build production AI agents” is not a single leap. It’s a ladder. And most people are skipping the middle rungs.
I’ve spent nearly 30 years building enterprise data systems. Teradata, Snowflake, Databricks, ETL pipelines for Fortune 100 companies. When I started mapping AI onto enterprise architecture, I immediately recognized what was missing in every “AI agents learning path” I found online: the institutional knowledge of how real systems fail, scale, and get maintained.
This post is the learning path I wish existed when I started. It’s built for IT professionals and data engineers who want to build AI agents that actually work in production, not just impress audiences at meetups.
Why Most “Learning Paths” Are Designed for the Wrong Person
Search for “AI agents learning path” right now. What do you find? Bootcamp-style content designed for people with no prior technical background. Twenty-one week programs. Certificate courses from platforms that also sell you JavaScript for beginners.
That’s not you.
You’ve architected distributed systems. You understand latency, throughput, and failure modes. You’ve watched “promising technology” get adopted by enterprises and then abandoned when it couldn’t scale or be maintained. You have context that a six-month bootcamp grad doesn’t have.
That context is a superpower, but only if you apply it correctly. The path I’m laying out here respects your background and explains each step from an enterprise architect’s perspective.
Step 1: LLM Fundamentals (Reframe What You Already Know)
Why it matters for enterprise: You can’t build reliable systems on top of technology you treat as a black box.
I’m not saying you need to read research papers or implement transformer architectures from scratch. But you do need to understand how LLMs actually work at a conceptual level: tokens, context windows, temperature, the difference between a base model and a fine-tuned model. More importantly, you need to understand what LLMs are bad at.
LLMs have no memory by default. They can’t access your data. LLMs hallucinate with complete confidence. They’re stateless. Every one of those limitations has a mitigation strategy, and the entire agent architecture stack is essentially a series of wrappers built to address those core limitations.
Coming from enterprise data, think of an LLM like a very smart query engine with no schema awareness and no persistent storage. Everything you learned about data quality, governance, and reliability still applies. It just applies at a different layer.
What to focus on: – Context windows and why they matter for long-running enterprise tasks – Token costs and how they map to real operational budgets – The difference between instruction-following models (GPT-4o, Claude) and reasoning models (o1, o3) – Basic API usage with OpenAI or Anthropic SDKs
Step 2: Prompt Engineering (Not as Simple as It Sounds)
Why it matters for enterprise: Prompts are code. Treat them that way.
For matures who are just getting used to using AI, it’s okay. But I see senior engineers dismiss prompt engineering as “just writing text.” That’s a mistake. In enterprise AI systems, a prompt is a specification. A poorly written prompt in a production agent will give you inconsistent outputs at scale, which means inconsistent business logic running at machine speed.
Think of prompt engineering like writing a stored procedure. You want it deterministic, testable, and maintainable by someone who didn’t write it originally. The “vibes-based” prompting that works fine in demos breaks down when you’re running thousands of calls per day.
Key concepts to master: – System prompts vs. user prompts vs. few-shot examples – Chain-of-thought prompting for multi-step reasoning tasks – Structured output (JSON mode, response schemas) to keep outputs machine-parseable – Prompt versioning and testing (yes, you should be testing your prompts like you test code)
The enterprise angle: start building a prompt library from day one. Version control it. Document the intent behind each design decision. Your future self will thank you.
Step 3: RAG (The Step Almost Everyone Skips Too Fast)
Why it matters for enterprise: This is where your data architecture experience pays off immediately.
Retrieval-Augmented Generation is the bridge between a generic LLM and a system that can reason over your company’s actual data. And this is the step where I see the most people rush through. They watch a 20-minute tutorial, build a basic PDF question-answering demo, declare victory, and jump to agents. That’s a mistake.
Here’s the reality: RAG is not a simple search feature. It’s a data pipeline. It has all the same problems your ETL pipelines have: data quality, freshness, chunking strategy, schema drift, retrieval accuracy. As a data engineer, you already know how to solve most of these problems. You just need to apply that thinking to a new domain.
The components you need to truly understand:
Embedding models: How text gets converted to vectors. Which model you use affects retrieval quality significantly. OpenAI’s text-embedding-3-large is popular but evaluate alternatives based on your data domain.
Vector databases: Pinecone, pgvector (Postgres extension), Weaviate, Qdrant, ChromaDB. Enterprise selection criteria: Does it support your data governance requirements? Can it handle your data volume? Does it integrate with your existing auth systems?
Chunking strategy: This is where most tutorials are dangerously simplistic. Fixed-size chunking versus semantic chunking versus hierarchical chunking. The right strategy depends on your document types. A legal contract has a different optimal chunking strategy than a product catalog.
Retrieval quality: Semantic search alone is often not enough. Hybrid retrieval (vector search combined with keyword/BM25 search) typically outperforms pure vector search for enterprise use cases where specific terminology matters.
Evaluation: How do you know your RAG system is actually retrieving the right context? You need an evaluation framework: RAGAS or similar. In enterprise, “it seems to work” is not acceptable. You need metrics.
The enterprise angle: treat your vector store like a data warehouse. Have a loading process. Have quality checks. Have a refresh strategy. Document your chunking decisions like you’d document a data model.
Tools and frameworks: LlamaIndex is the gold standard for RAG-heavy systems. LangChain also works but I find LlamaIndex cleaner for purely RAG-focused work.
Step 4: Tool Calling (Where LLMs Start Acting)
Why it matters for enterprise: Tool calling is the mechanism that connects LLMs to your existing systems.
Tool calling (also called function calling) lets an LLM decide when to invoke an external function, what parameters to pass, and how to use the result. This is the capability that turns a chatbot into a system that can actually do things.
From an enterprise architecture perspective, think of tool calling like an API integration layer with intelligent routing. The LLM reads a tool’s description and decides whether to call it. Your job as the engineer is to write tool descriptions that are clear enough for the model to use correctly, and to build tools that return clean, structured responses.
What to build in this phase: – Tools that read from and write to your existing databases – Tools that call internal REST APIs – Tools that perform calculations or data transformations – Error handling and retry logic inside tools (LLMs don’t handle vague error messages well)
The enterprise angle: treat every tool like a microservice. Clear interface, single responsibility, proper logging, and error handling. Tools in an agent system get called autonomously, often thousands of times per day. Build them accordingly.
Step 5: Agent Frameworks (Choose Based on Production Requirements)
Why it matters for enterprise: The framework you choose determines your ceiling, not just your starting point.
This is where most tutorials focus almost exclusively, and where they give the worst advice: “just pick the one with the most GitHub stars.” In enterprise, you’re evaluating frameworks the same way you’d evaluate any infrastructure component.
Let me give you the honest comparison of the three frameworks I get asked about most often.
LangGraph
LangGraph represents agents as stateful graphs. Nodes are functions or LLM calls. Edges define the flow between them, including conditional branching. The framework gives you fine-grained control over state management, which means you can implement complex multi-step workflows with precise error handling and recovery logic.
Enterprise strengths: – Explicit state management makes workflows auditable and debuggable – Conditional edges let you implement complex business logic – Human-in-the-loop patterns are well-supported (critical for regulated industries) – Strong community and LangChain ecosystem integration
Enterprise concerns: – Steeper learning curve than alternatives – More verbose code for simpler use cases – LangChain ecosystem has had some API stability issues historically
Best for: Complex, multi-step workflows where you need precise control and auditability. Financial services, healthcare, any domain where you need to explain exactly what the agent did and why.
Google ADK (Agent Development Kit)
Google’s ADK is a higher-level framework designed for building and deploying agents, particularly within the Google Cloud ecosystem. It handles a lot of the scaffolding that LangGraph requires you to build yourself.
Enterprise strengths: – Native integration with Google Cloud (Vertex AI, BigQuery, GCS) – Enterprise-grade security and IAM patterns – Designed for production deployment from the start – Multi-agent orchestration built in
Enterprise concerns: – If you’re not on Google Cloud, the value proposition weakens significantly – Still relatively new. The tooling is maturing but not as battle-tested as LangGraph – Ecosystem lock-in is real
Best for: Organizations already invested in Google Cloud who want the fastest path to production. GCP-native data teams coming from BigQuery and Vertex AI environments.
CrewAI
CrewAI uses a role-based metaphor: you define agents with specific roles, assign them tasks, and they collaborate to complete a goal. It’s the most intuitive framework to pick up, which is why it dominates tutorials and demos.
Enterprise strengths: – Fastest time to a working prototype – Role-based model is easy to explain to non-technical stakeholders – Good for use cases that naturally map to team-based workflows
Enterprise concerns: – Less control over low-level execution details – State management is more opaque than LangGraph – Production deployments at scale surface limitations quickly – Debugging complex failures is harder
Best for: Prototyping, internal tooling, proof-of-concept work. I would not build a customer-facing production system on CrewAI without careful evaluation of its limitations.
My recommendation for enterprise: Learn LangGraph first. It will feel harder, but the control it gives you is worth it for production systems. Use CrewAI for rapid prototyping. Consider Google ADK if you’re Google Cloud-first.
Step 6: Multi-Agent Systems (Enterprise Architecture at the AI Layer)
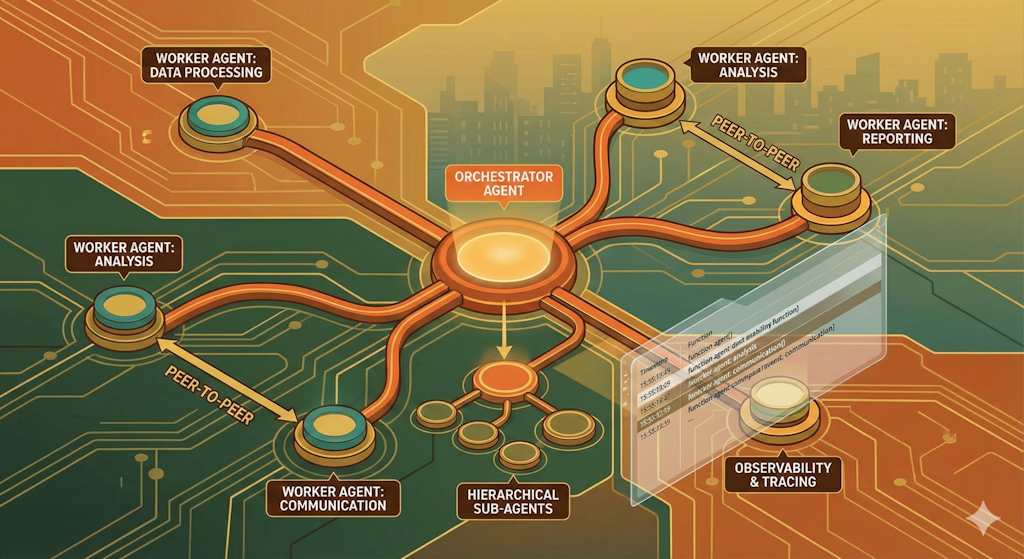
Why it matters for enterprise: Single agents hit context and capability limits. Multi-agent systems are where your distributed systems experience becomes invaluable.
A multi-agent system divides complex tasks across specialized agents, the same way microservices divide complex applications across specialized services. You have an orchestrator agent that plans and delegates, and worker agents that execute specific tasks.
The patterns you already know from distributed systems apply here: routing, load balancing, error handling, retry logic, circuit breakers. The concepts translate. The implementation is new.
Key patterns to understand: – Supervisor/worker: one orchestrator delegates to specialized sub-agents – Peer-to-peer: agents communicate directly, good for negotiation tasks – Hierarchical: layered orchestration for very complex workflows
The enterprise angle: design your multi-agent system with observability from the start. You need to trace which agent called which tool, with what inputs, and what it returned. Without that, debugging production failures is painful.
Step 7: Production Deployment (Where Most Tutorials Stop)
Why it matters for enterprise: Building an agent is maybe 20% of the work. Operating it is the other 80%.
This is where your enterprise background gives you a massive advantage over people who learned AI from bootcamps. You already know that systems fail. You already know that monitoring, alerting, and runbooks matter. You already know about capacity planning, SLAs, and incident response.
Apply all of that to your AI agent systems.
Production checklist: – Observability: LangSmith (LangChain ecosystem) or similar for tracing agent execution. You need to see every step, every token, every tool call. – Cost controls: Token budgets, rate limiting, circuit breakers to prevent runaway agent loops – Testing: Unit tests for tools, integration tests for agent workflows, golden dataset evaluation for RAG – Guardrails: Input validation, output validation, content filtering for regulated industries – Human-in-the-loop: Escalation paths when agent confidence is low or stakes are high – Versioning: Prompts, tools, agent configurations. All version-controlled.
The Honest Timeline
If you already have a strong technical background, here’s a realistic timeline:
- Weeks 1-2: LLM fundamentals and API basics
- Weeks 3-4: Prompt engineering, structured outputs
- Weeks 5-8: Spend real time here. Build two or three different RAG systems on different types of data.
- Weeks 9-10: Tool calling, building integrations to your existing systems
- Weeks 11-14: Agent frameworks. Start with LangGraph. Build real workflows.
- Weeks 15-16: Multi-agent patterns
- Ongoing: Production deployment, evaluation, iteration
That’s about three to four months of focused learning to be genuinely capable. Not weeks. Not a weekend. Four months.
Why Enterprise Experience Is Actually an Advantage
I want to address something I hear from experienced professionals: “I feel behind because I don’t have a machine learning background.”
You’re not behind. You’re approaching this from a different angle, and in many ways a better one.
Bootcamp grads know how to build a demo. They’ve seen two frameworks and one deployment pattern. You know how data gets corrupted at scale. You know what happens when a system handles ten times the expected load. You know what “enterprise security requirements” actually means because you’ve navigated them.
Every AI agent system eventually runs into the same problems that every enterprise system runs into: data quality, latency, cost control, access management, auditability. You’ve already solved most of those problems in a different context.
The AI layer is new. The engineering discipline underneath it is not.
What’s Next for You
I built this exact learning path into structured courses because I kept seeing the same gaps in what was available. Most AI courses are either too shallow (get a demo working in three hours) or too academic (here’s the math behind transformers).
What’s missing is the enterprise lens: how do these concepts apply when you have real data governance requirements, real SLAs, and a real organization that needs to trust what you build?
If you’re an IT professional or data engineer who wants to build AI agent systems that work in production, not just in demos, I’d like to help you get there. I’ve trained hundreds of students through this path and I know exactly where people get stuck and why.
Visit gauraw.com to see current courses and resources. If you want to talk through your specific situation and figure out where to start, reach out directly. I answer every message.
The opportunity in enterprise AI is real. The window to develop genuine expertise, before every organization has a team of people who know how to build these systems, is open right now. Use it.